
Character Encoding과 Base64
WEB - 문자열 인코딩
Encode의 사전적 의미는 암호화하다 부호화(주어진 정보를 어떤 표준적인 형태로 변환하거나 거꾸로 변환하다)하다이다.
Character encoding
문자열 인코딩(Character encoding)은 human language에 사용되는 문자(기호)에 숫자를 대응(assign)시키는 작업이다. 문자를 숫자로 변환하여 digital computer를 통해 저장, 전송하는 것이 목적이다.
문자(또는 기호)에 대응되는 숫자 값 하나를 code point라고 한다. Code point가 모여서 code space, code page 또는 code map을 구성한다.
ASCII
ASCII(American Standard Code for Information Interchange)는 전자 통신을 위한 문자열 인코딩 표준이다. 128개의 code point로 구서오디어 있으며 그 중 출력 가능한 문자는 95개이다. 전 세계에 존재하는 대부분의 문자 체계를 표현할 수 있는 Unicode code point의 첫 128개는 ASCII와 일치한다. 그렇기 때문에 ASCII로 인코딩된 텍스트는 Unicode로 쉽게 변환된다.
How Base64 works
Base64는 binary data를 printable text(ASCII 문자열)로 변환하는데 사용된다.
문자열 “Hi”가 Base64 방식으로 인코딩되는 과정은 아래와 같다.
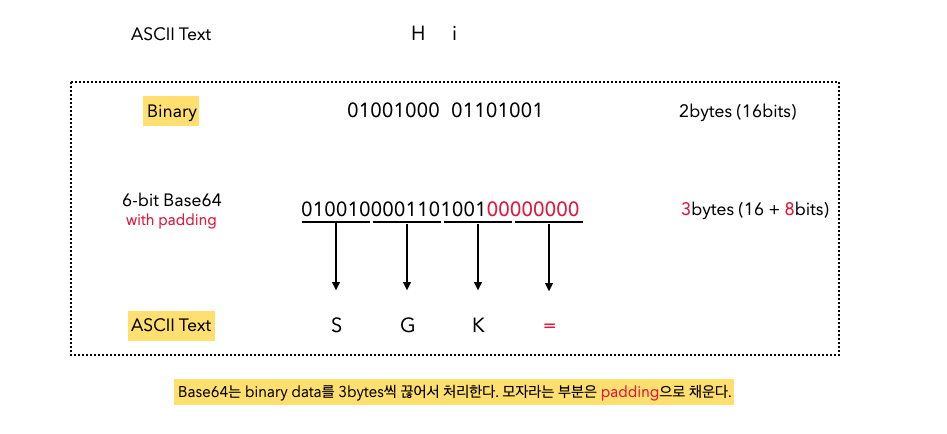
Binary data를 3bytes씩 묶고 그 묶음 안에서 6bits씩 끊어서 4개의 ASCII Text로 변환한다. 각 3bytes가 4개의 ASCII 문자로 대응되기 때문에 문자열의 길이가 증가한다.
Decoding은 역변환이다. 문자열을 다시 binary data로 변환한다.
일반적으로 Character encoding은 문자를 binary data(sequence of bytes)로 변환하지만 Base64 Encoding은 binary data를 문자로 변환한다.
Base64 인코딩을 사용하는 이유
전송 매채(프로토콜)가 ASCII 문자열만을 안전하게 전송하는 경우 사용된다. 이메일 전송 프로토콜(SMTP)의 초기 버전은 ASCII 텍스트의 전송만을 지원하였다. 이미지와 문서, 프로그램 등의 binary data를 전송하기 위해 Base64 인코딩으로 ASCII로 변환하여 이메일에 포함할 수 있었다.
Raw binary data는 컴퓨터마다, 프로토콜마다 해석하는 방법이 다르기 때문에 안전한 전송을 보장할 수 없다. 예를 들어 시스템 A에서는 null 문자가 단순히 개행을 의미하지만 데이터를 전달하는 시스템 B에서는 null 문자를 데이터의 종료로 해석하는 경우, 데이터의 일부만 전송되게 된다.
Comments