
기사 수집 모듈
KeywordKatch - 기사 수집
기사를 분석하려면 충분한 양의 기사가 필요해서 100개정도만 기사를 수집하는 모듈을 만들었다.
기사는 조선일보에서 수집했다.
single threaded crawler
하나의 쓰레드가 RSS의 모든 기사를 다운받아 디스크에 쓰도록 구현했다.
코드
def get_body(article_url):
context = ssl._create_unverified_context()
with urlopen(article_url, context=context) as html:
bs = BeautifulSoup(html, 'html.parser')
body = bs.find('section', {'class': 'article-body'})
if body == None:
return None
else:
return body
################################ main ################################
# [patch] load module
from importlib.machinery import SourceFileLoader
article_chosun = SourceFileLoader("article", "/Users/mingeun/study/crawling/oreilly/article.py").load_module()
article_links = {}
# Feed에서 기사 목록 획득
with urlopen(CHOSUN_RSS) as feed:
root = ET.fromstring(feed.read())
items = root.find('channel').findall('item')
for item in items:
title, link = None, None
# <item>
for child in item:
if child.tag == 'title' and child.text != None:
title = child.text
elif child.tag == 'link' and child.text != None:
link = child.text
article_links[title] = link
# </item>
# prepare article archive
if not os.path.exists(ARTICLE_ARCHIVE_PATH):
try:
os.mkdir(ARTICLE_ARCHIVE_PATH)
except OSError as e:
print('[mkdir] ERROR')
exit()
for title in article_links:
print(title + ': ' + article_links[title])
print('collected {0} links.'.format(len(article_links)))
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
# fetch articles to disk
count = 0
TOTAL_COUNT = len(article_links)
print('\033[?25l') # hide cursor
start = time.time()
for title in article_links:
print('\r%-15s %-0.1f%%' %('crawling...', count/TOTAL_COUNT*100), end='')
driver.get(article_links[title])
try:
element = WebDriverWait(driver, 3).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'section.article-body')))
finally:
body = driver.find_element(By.CSS_SELECTOR, 'section.article-body')
if body == None:
print("{0} : none...".format(article_links[title]))
else:
body = body.text
to_file(title, body)
count += 1
end = time.time()
print('\r%-15s %-0.1f%%' %('crawling...', 100), end='')
print('\033[?25h') # show it back
print('\r%-30s %0.2fseconds' %('finished', end-start))
performance

- elapsed time for 100 articles: 755.42s
- average time for 1 article: 7.6s
- expected time for 10000 articles: 21m
multi-threaded crawler
실행 환경
Processor - Apple M1
RAM - 8G
DISK - SSD
[Approach 1] n개의 작업(load+write)을 동시에 실행
2개 이상의 thread가 RSS에서 동시에 기사를 가져오도록 구현했다.
각thread는 기사를 다운(인터넷에서 메모리로 load)받아 디스크에 저장(write)한다.
def crawler(tnum, articles, start, end, progress):
"""
Load articles in quota and write them to dest as file.
start - int value, included.
end - int value, excluded.
"""
count = 0
# prepare webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
for article in articles[start:end]:
driver.get(article[INDEX_URL])
try:
element = WebDriverWait(driver, 3)\
.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'section.article-body')))
body = driver.find_element(By.CSS_SELECTOR, 'section.article-body')
body = body.text
to_file(article[INDEX_TITLE], body)
count += 1
progress = (count/(end-start))*100
except TimeoutException:
print('pass: %s' % article[INDEX_URL])
continue
driver.close()
print('thread%s finished. Collected %d articles' % (tnum, count))
def Main():
global NUMBER_OF_THREAD
# set the number of thread
if len(sys.argv) != 1:
NUMBER_OF_THREAD = int(sys.argv[1])
# get targets
article_infos = get_articles()
# cli info
for article in article_infos:
print(article[INDEX_TITLE] + ': ' + article[INDEX_URL])
print() # empty line
mkarch()
print('collected {0} links.'.format(len(article_infos)))
################### multi threading code start ###################
# calcuate the number of articles per thread to collect(read+write)
TOTAL_COUNT = len(article_infos)
articles_per_thread = math.ceil(TOTAL_COUNT/NUMBER_OF_THREAD)
# create threads
workers = []
workload = [0]*(NUMBER_OF_THREAD+1) # amount of article to be collected per one thread
progress = [0]*(NUMBER_OF_THREAD+1)
quota = int(TOTAL_COUNT/NUMBER_OF_THREAD)
rest = TOTAL_COUNT % NUMBER_OF_THREAD
for t in range(1, NUMBER_OF_THREAD+1):
workload[t] = quota
if rest > 0:
workload[t] += 1
rest -= 1
# start threads
start_t = time.time()
print() # empty line
for t in range(1, NUMBER_OF_THREAD+1):
print('thread%d - %d articles' %(t, workload[t]))
start_idx = quota * (t-1) + 1 # start_idx
end_idx = start_idx + quota # end_idx
try:
worker = threading.Thread(target=crawler, args=(t, article_infos, start_idx, end_idx, progress))
workers.append(worker)
worker.start()
except Exception as e:
print('[ERROR] %s' % e)
for worker in workers:
worker.join()
end_t = time.time()
print('\r%-30s %0.2fseconds' %('finished', end_t-start_t))
if __name__ == '__main__':
Main()
performance - 2threads
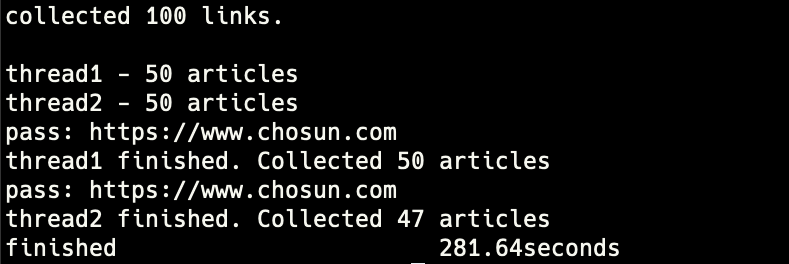
- elapsed time for 100 articles: 281.64s
- average time for 1 article: 2.82s
- expected time for 10000 articles: 8m
performance - 3threads
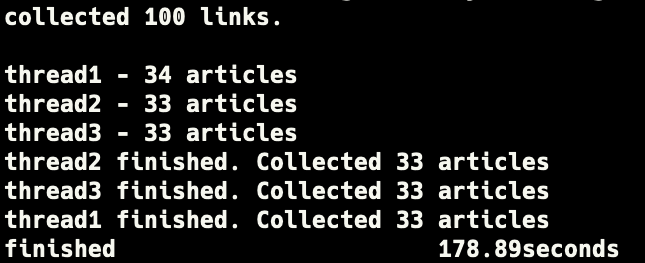
- elapsed time for 100 articles: 178.89s
- average time for 1 article: 1.79s
- expected time for 10000 articles: 5m
performance - 4threads
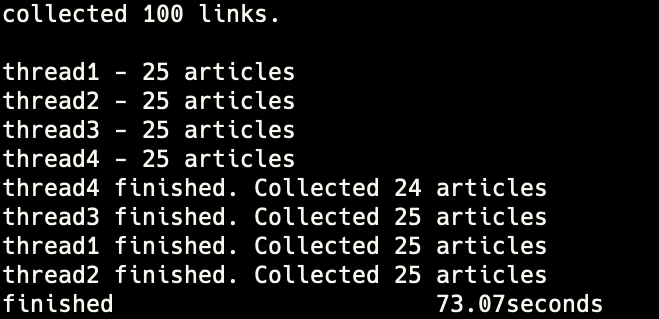
- elapsed time for 100 articles: 73.07s
- worst case: 103s
- best case: 44s
- average time for 1 article: 0.73s
- expected time for 10000 articles: 2m
cost
4개의 쓰레드에서 chrome driver가 사용하는 메모리는 평균 450.25MB였다.

[Approach 2] load, write 작업을 동시에 실행
위의 경우와 다르게 network I/O와 disk I/O를 분리하였다. 각각의 작업은 두 종류의 쓰레드에서 동시에 실행된다.
disk_worker- queue에 저장된 기사를 디스크에 파일로 저장crawler- 인터넷에서 수집한 기사를 queue에 저장
이 코드에는 deadlock을 일으킬 수 있는 오류가 포함되어 있다.
def disk_worker(tnum, queue, working_crawler):
"""
Write article to disk while 'queue' is not empty.
tnum - Thread number.
queue - Thread-safe queue. Element is tuple(title, body).
working_crawler - If this queue and queue is empty, stop this thread.
"""
while not working_crawler.empty():
while not queue.empty():
title, body = queue.get()
to_file(title, body)
def crawler(tnum, articles, start, end, progress, queue, working_crawler):
"""
Load articles in quota and write them to dest as file.
start - int value, included.
end - int value, excluded.
queue - Buffer for the articles. disk_worker function will flush buffer items to disk.
"""
count = 0
working_crawler.put(tnum)
# prepare webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
for article in articles[start:end]:
driver.get(article[INDEX_URL])
try:
element = WebDriverWait(driver, 3)\
.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'section.article-body')))
body = driver.find_element(By.CSS_SELECTOR, 'section.article-body')
body = body.text
queue.put((article[INDEX_TITLE], body))
count += 1
progress = (count/(end-start))*100
except TimeoutException:
print('pass: %s' % article[INDEX_URL])
continue
driver.close()
working_crawler.get() # Remain elements are not exactly match to working threads' tnum. Only the number of the elemnts is correct.
print('thread%s finished. Collected %d articles' % (tnum, count))
performance
기사 수집 모듈의 성능(쓰레드 개수에 따른 실행 시간)을 측정을 자동화 했다.
PYTHON=`which python3`
TEST_NUMBER=10
if [ $# -eq 2 ]
then
TEST_NUMBER=$1
fi
for (( i=1; i<=$TEST_NUMBER; i++))
do
echo -e "\ntest[$i]...\n"
$PYTHON my_scraper.py 3
done
크롤링을 10번 실행하고 각각에 대해서 테스트 시작 시각, 걸린 시간, crawler 개수, disk_worker 개수 등을 기록했다.
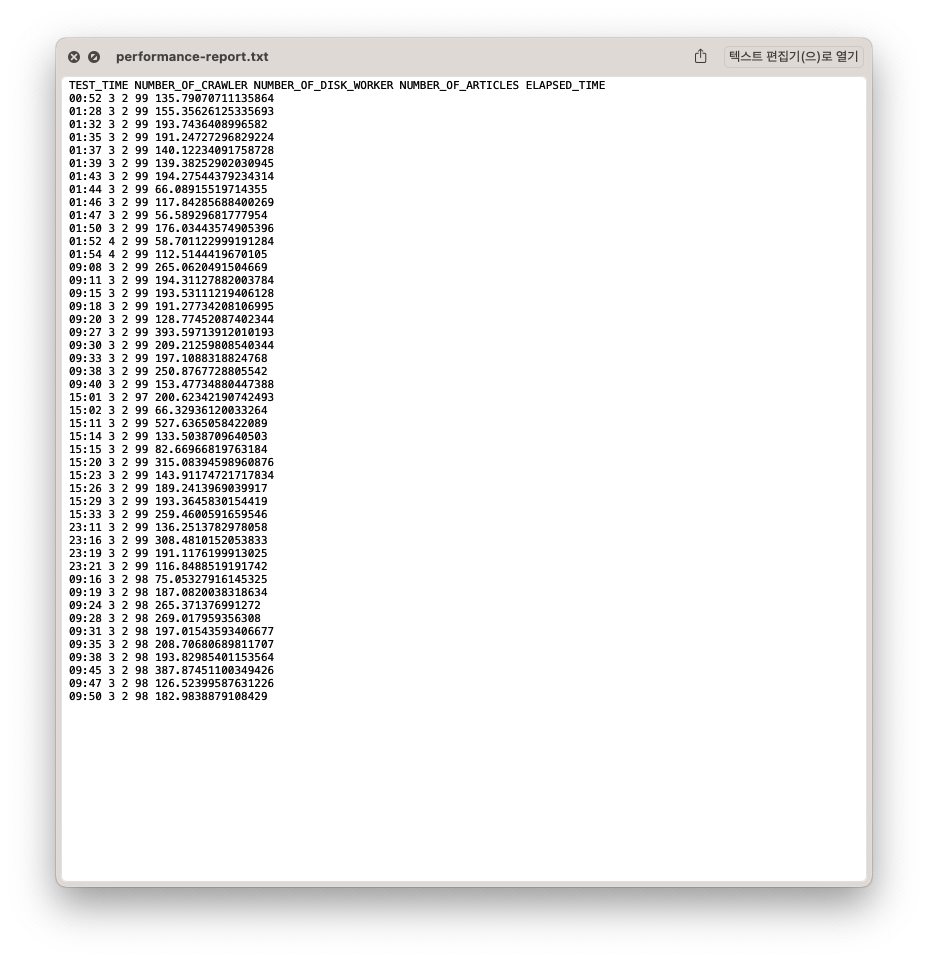
Troubleshooting
병렬 스크래핑 기능 구현 중 발생했던 문제
[Problem 1] TimeoutException, NoSuchElementException
driver가 지정된 HTML element를 찾지 못한 채 timeout만큼의 시간이 지날 경우 발생한다.
solution
timeout을 3초로 설정했는데 3초 안에 렌더링이 끝나지 않는 경우가 많지 않기 때문에 해당 예외가 발생하면 다음 기사로 넘어가도록 구현했다.
for article in articles[start:end]:
driver.get(article[INDEX_URL])
try:
element = WebDriverWait(driver, 3)\
.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'section.article-body')))
body = driver.find_element(By.CSS_SELECTOR, 'section.article-body')
body = body.text
to_file(article[INDEX_TITLE], body)
count += 1
progress = (count/(end-start))*100
except TimeoutException:
print('pass: %s' % article[INDEX_URL])
continue
driver.close()
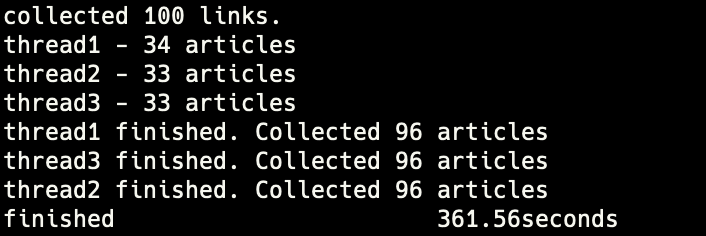
100개 중 4개를 건너뛰고 96개만 수집했다.
[Problem 2] Deadlock
자주는 아니지만 가끔 crawler 쓰레드가 종료된 뒤에 데드락 상태에 빠져 프로그램이 실행되지 않는 문제가 발생했다.
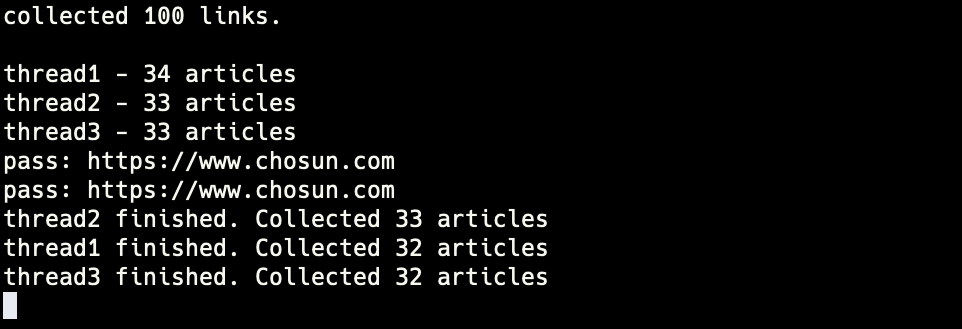
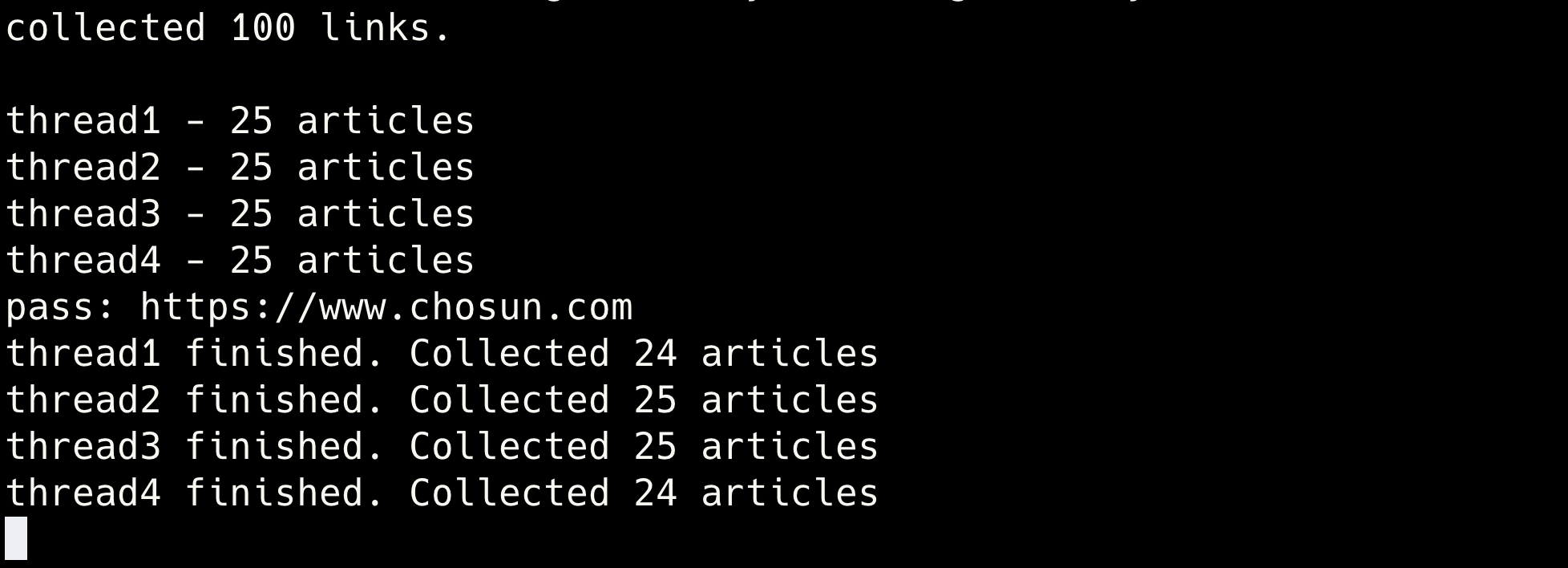
원인 분석
crawler 쓰레드는 정상적으로 종료되었기 때문에 문제가 되는 코드는 그 이후일 것이다.
(thread1 finished … 메세지는 크롤러가 종료되면 출력되기 때문이다)
# wait for workers
for cralwer in crawlers:
crawler.join()
for worker in disk_workers:
worker.join()
end_t = time.time()
print('\r%-30s %0.2fs' %('finished', end_t-start_t))
모든 crawler가 종료된 이후부터는 disk_worker가 종료되기를 기다리는데 disk_crawler가 종료되지 않아 문제가 발생한 것이였다. 그렇다면 disk_worker가 종료되지 않는 이유를 파악하면 문제를 해결할 수 있다.
def disk_worker(tnum, queue, working_crawler):
"""
Write article to disk while 'queue' is not empty.
tnum - Thread number.
queue - Thread-safe queue. Element is tuple(title, body).
working_crawler - If this queue and queue is empty, stop this thread.
"""
while not working_crawler.empty():
while not queue.empty():
title, body = queue.get()
to_file(title, body)
위의 코드는 queue의 item이 한 개 남았을 때 문제가 발생한다.
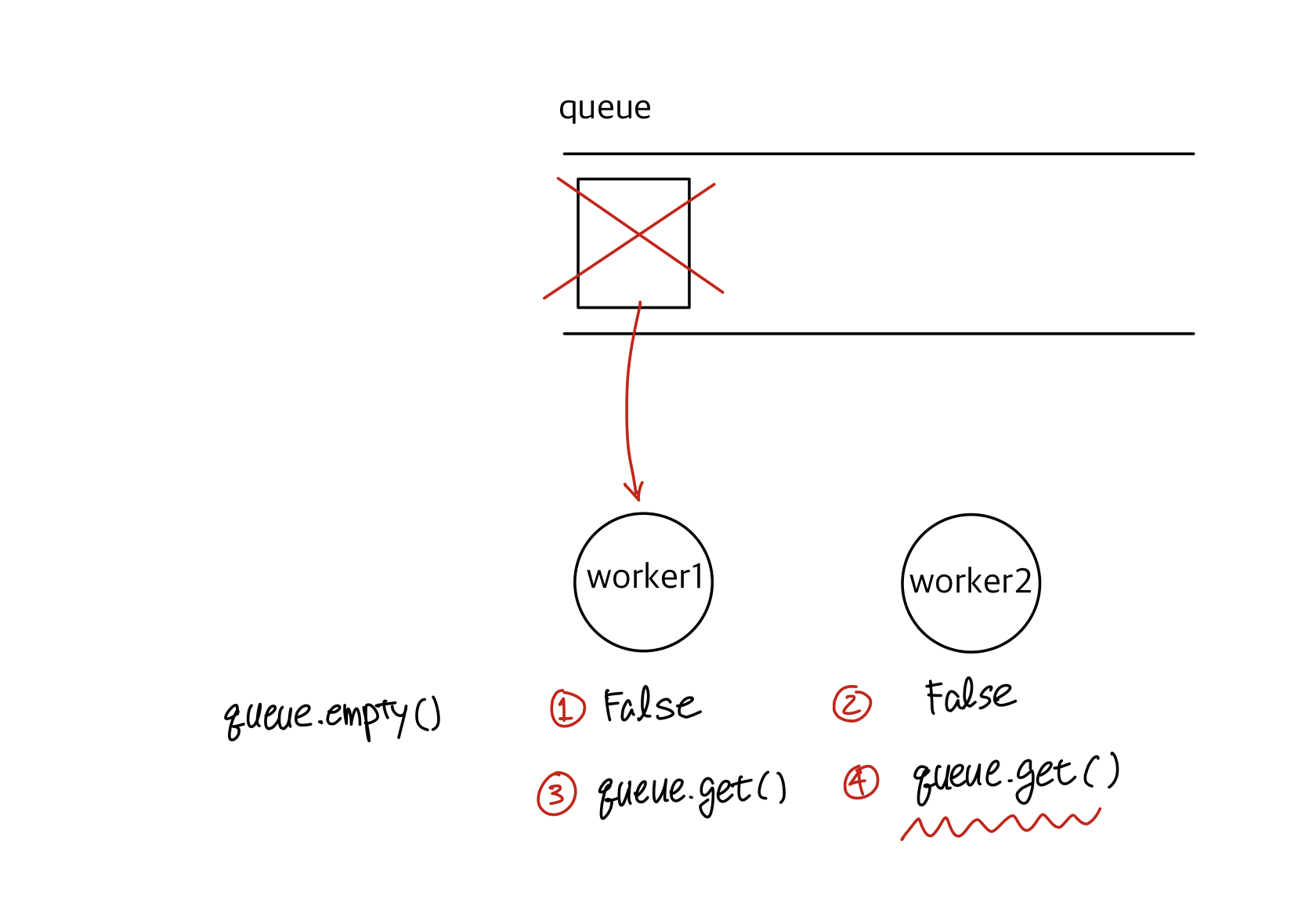
① 먼저 worker1에서 queue.empty() 호출 결과 False가 반환
context switching
② worker2에서도 queue.empty()의 결과가 False
context switching
③ worker1에서 queue.get() 호출 => queue의 item을 가져간다.
context switching
④ worker2에서 queue.get()을 호출하지만 queue가 비었기 때문에 block
solution
위와 같은 상황이 발생할 수 있기 때문에 Queue.empty()의 결과가 Empty라고 해서 반드시 Queue.get()이 성공하는 것은 아니다. 예기치 못한 다른 쓰레드의 접근으로 Queue의 item이 사라지면 사용 가능한 item이 확보될때까지 block 된다.
def disk_worker(tnum, queue, working_crawler):
while not working_crawler.empty():
try:
title, body = queue.get(timeout=2)
to_file(title + '.txt', body)
except Empty:
continue
while not working_crawler.empty()를 통해 현재 실행중인 크롤러가 있는지 확인한다. disk_worker의 속도가 crawler의 속도보다 빨라서 disk_worker가 종료된 후에 새로운 기사가 메모리에 로드되는 현상을 막기 위함이다.
Comments