
기사를 대표하는 키워드 추출
KeywordKatch - analyzer
크롤링을 통해 수집한 기사들로부터 그 내용을 대표하는 키워드를 추출하는 방법
메모리 사용량을 최소화하기 위해 외부 라이브러리, 인공지능의 도움을 받지 않고 구현했다.
TF.IDF
TF.IDF는 임의의 문서에 있는 특정 단어가 얼마나 중요한지를 수치화하는 방법이다. 글의 주제와 관련된 indicator는 일반적으로 보기 드문 단어이지만 해당 문서에서는 자주 등장하게 된다. 각 단어에 대한 TF.IDF점수는 TF값과 IDF값을 곱해서 계산한다.
TF.IDF 점수가 높을수록 문서의 주제와 관련되어 있을 확률이 높다.
Term Frequency
하나의 문서에서 자주 등장하면 커지는 값이다.
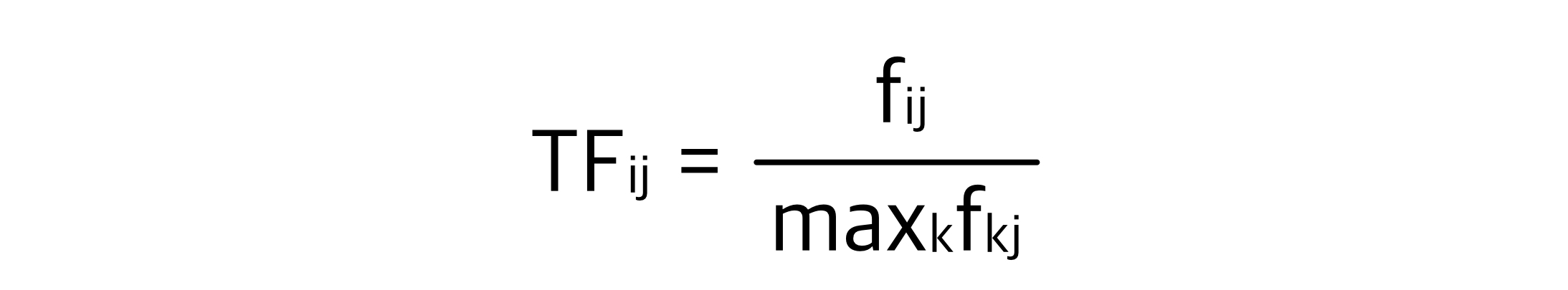
- fij: j번째 문서의 i번째 단어가 등장한 횟수
- maxkfkj: 문서 j에서 가장 많이 등장한 단어 k의 등장 횟수
Inverse Document Frequency
여러 문서들에서 자주 등장할수록 낮아지는 값이다.
일반적으로 등장하는 do, are, is, …와 같은 단어들(stop word라고 한다)의 점수를 낮춰준다.
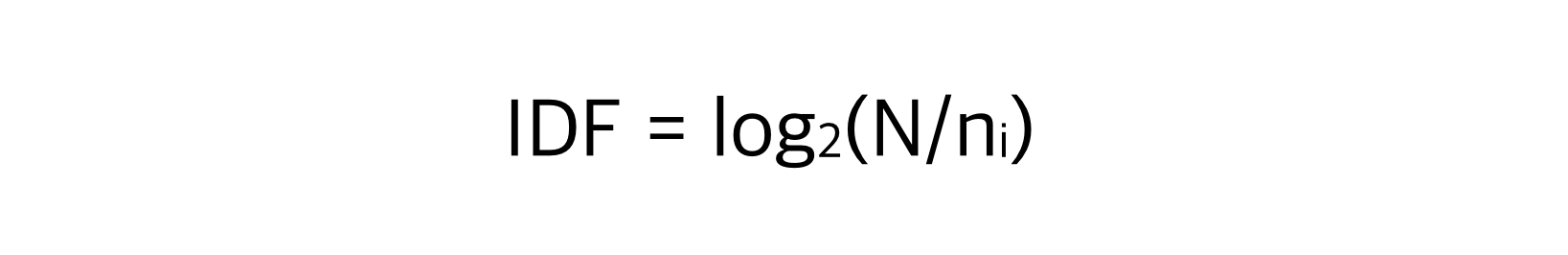
- N: 전체 문서의 개수
- ni: 단어i가 한 번이라도 등장한 문서의 개수
- log2: N과 ni의 크기가 매우 클 경우 전체 값이 너무 크지 않게 만들어준다
전처리
정규 표현식을 사용하여 수집한 기사들에서 구두점, 괄호 등의 기호를 제거했다.
def refine(content):
'''
의미 없는 기호(탈출문자, 구두점 등)를 제거한다.
'''
content = re.sub('[\t\n()=.<>◇\[\]"“‘”’·○▲△▷▶\-,\']', ' ', content)
return content
파이프라인
컴퓨터 과학에서 파이프라인은 한 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 구조를 의미한다.
하나의 기사는 다음과 같은 파이프라인을 거쳐 키워드가 추출된다. 기존의 TF-IDF를 상황에 맞게 변형했다.
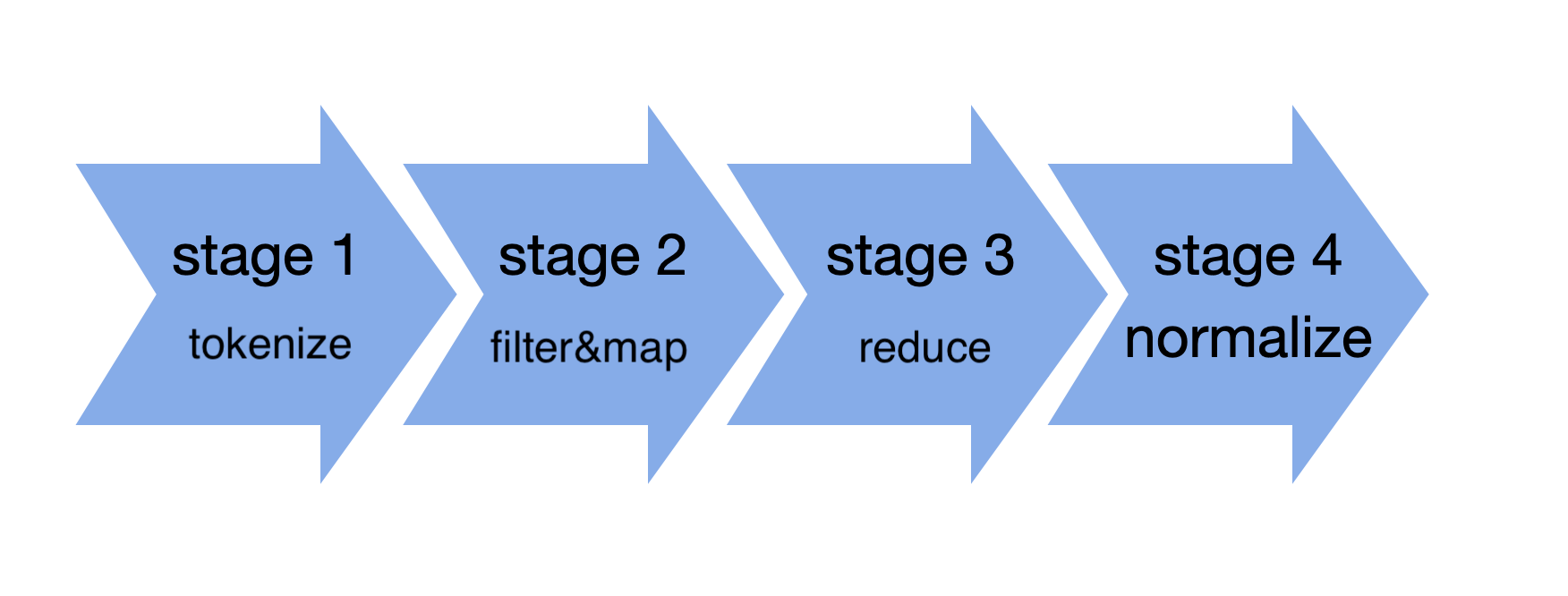
지금부터 등장하는 예시는 3.26 11개의 언론사에서 수집한 1178개의 기사를 분석한 것이다. (동아, 이데일리, 파이낸셜, 한겨레, 한경, 헤럴드, jtbc, sbs, 경향, 매일, mbn)
- 프로세서: M1 chip
- main memory: 8GB
- secondary memory(디스크라고 표현했다): SSD
stage1-tokenize
디스크에서 모든 기사를 읽어들인다. 그리고 띄워쓰기를 기준으로 나누어 토큰을 생성한다. 여기서 토큰이란 공백으로 구분되는 텍스트의 단위이다. 토큰을 생성하며 구두점, 특수기호 등이 제거되고 토큰의 개수를 기록한다.
- 걸린 시간: 0.23s (O(N), N은 character 개수)
- 생성된 토큰: 324,615개 (기사 한 개당 평균 토큰 개수: 276개)
stage2-filter&map
stage1의 결과에서 토큰의 길이가 3~10인 것들만 남기고 나머지는 버리고 남은 토큰의 개수를 기록한다. 일반적으로 명사에 조사가 붙는데 길이가 1,2인 토큰은 의미 있는 명사라고 생각하기 힘들기 때문이다.
- 걸린 시간: 0.02s (O(N), N은 토큰의 개수)
- stage1 대비 토큰 개수 33% 감소 (324,615 -> 218, 819)
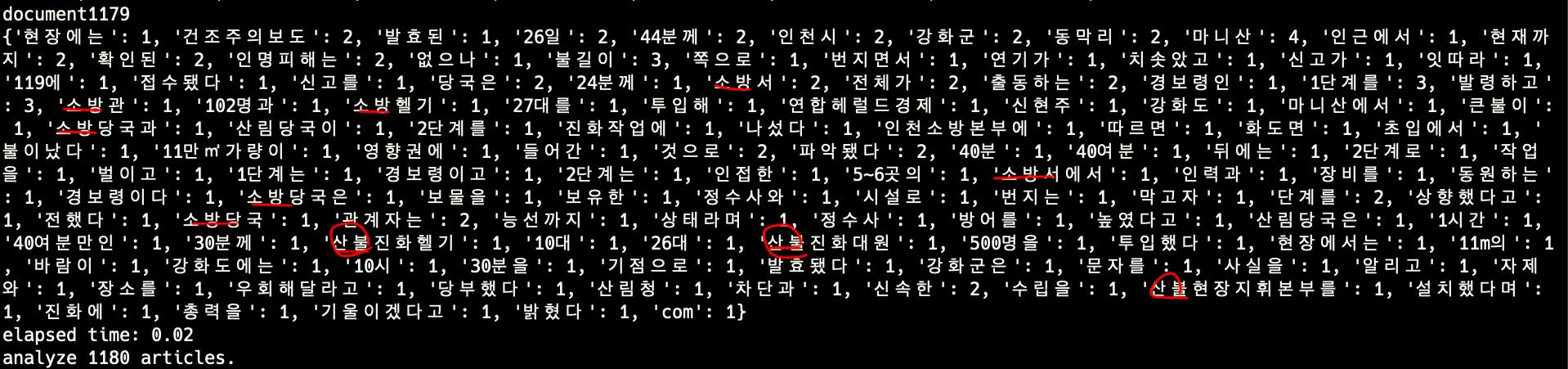
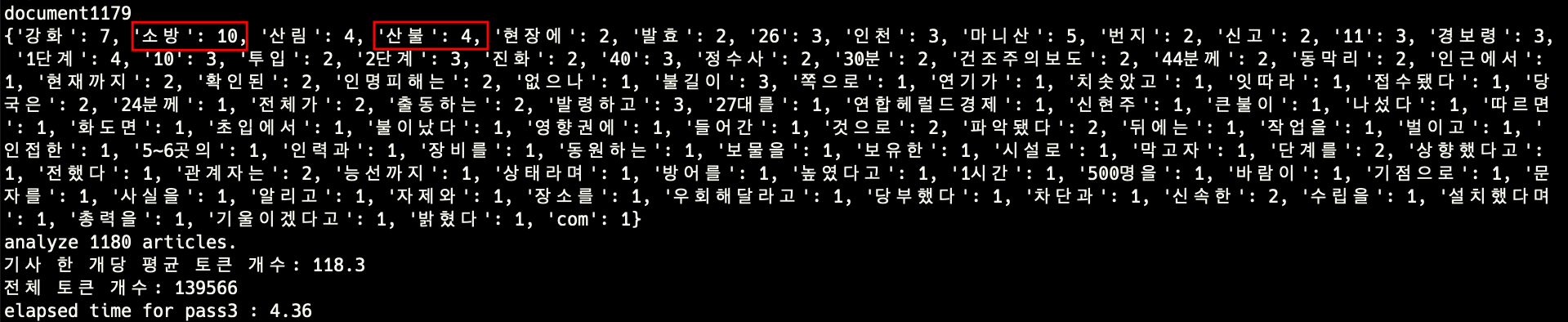
stage3-reduce
stage2의 결과에서 비슷한 토큰을 합치고 그 개수를 기록한다.
예를 들어 하나의 기사에서 “산불진화헬기를”, “산불진화대원들”, “산불현장지휘본부를” 이라는 토큰이 등장했다면 세 개의 토큰을 모두 하나로 생각하는 것이 주제를 파악하는데 도움이 된다. reduce 과정을 통해 이런 토큰들을 하나로 합친다. 토큰을 합치는 기준은 두 토큰 중 짧은 토큰을 기준으로 30% 이상 일치하는지 여부이다. 이 과정에서 명사에 붙은 조사를 없앨 수 있다.
“산불진화헬기”, “산불현장지휘본부” 가 “산불”이라는 새로운 토큰으로 합쳐진다. 짧은 토큰인 “산불진화헬기”의 길이가 6인데 30%(2/6) 이상이 일치했기 때문이다.
- reduce 함수 두 번 호출에 걸린 시간: 4.41s (worst case O(N*N), N은 토큰 개수)
- stage2 대비 토큰 개수 37% 감소 (218,819 -> 139,565)
코드
def reduce(term_frequencies):
'''
하나의 문서에서 적당히 비슷한 토큰을 하나로 합친다.
term_frequencies - 하나의 문서에 대한 term_frequencies 딕셔너리(stage2의 결과)
{term: f, term: f, ...} 형태
'''
result = {}
reduced_keys = set()
terms = list(term_frequencies.keys())
for i, term in enumerate(terms):
if term not in reduced_keys:
for other in terms[i+1:]:
if is_reducable(term, other):
new_key = get_common_str(term, other)
if new_key in result:
result[new_key] += 1
else:
result[new_key] = term_frequencies[term] + term_frequencies[other]
reduced_keys.add(term)
reduced_keys.add(other)
# 합쳐지지 않은 토큰들을 보존한다.
for term in terms:
if term not in reduced_keys:
result[term] = term_frequencies[term]
return result
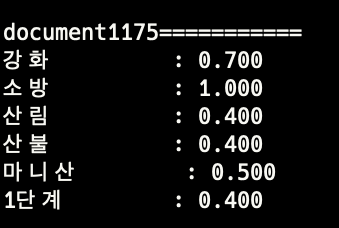
stage4-normalize
각 토큰의 등장 횟수를 0에서 1 사이의 값으로 정규화 한다. 각 토큰의 등장 횟수들의 차이가 너무 크면 중요한 토큰을 결정하기 위한 기준을 잡기 힘들기 때문이다. 간단하게 가장 자주 등장한 토큰의 빈도수로 각 토큰의 빈도수를 나누어준다.
keyword 결정
stage4의 결과에서 값이 0.3 이상인 값을 선택한다. 0.3이라는 수치는 경험적으로 결정했다.
기존의 TF-IDF와 다른 점
IDF는 계산하지 않았다. 적합하지 않았던 이유는 다음과 같다.
- 사회적으로 화제가 된 사건이 있었을 경우 그 사건에 대한 기사가 많이 수집된 경우 IDF가 의도에 맞지 않게 작용한다.
예를 들어 “황사”를 다룬 기사가 100개 중 50개였을 경우, “황사” 라는 키워드의 IDF 값이 매우 낮아진다. 이 키워드는 분명 기사의 주제와 관련이 있지만 IDF값이 낮아져 TF*IDF 전체 값이 낮아지기 때문에 키워드로 선택되지 않을 가능성이 커진다. - 시간이 오래 걸린다. (O(N*N) 고정, N은 토큰 개수)
Comments